Contributions
-
An empirical and systematic examination of VQGANs, leading to a modernized VQGAN.
-
A novel embedding-free generation network operating directly on bit tokens – a binary quantized representation of tokens with rich semantics.
VQGAN+: A Modern VQGAN
-
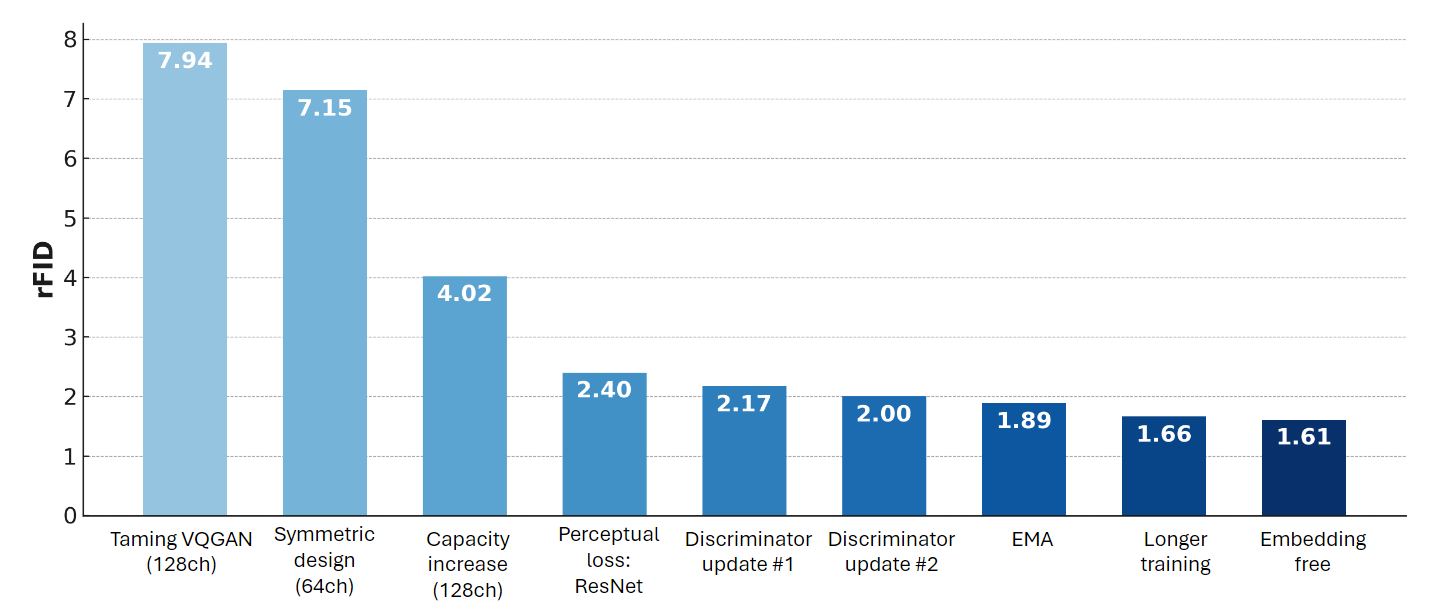
Basic Training Recipe and Architecture. The author makes four modifications and improve the 0.79 rFID on ImageNet from 7.94 rFID to 7.15rFID.
(1) Removing attention blocks for a purely convolutional design, which can reduce computational complexity without sacrificing performance.
(2) Adding symmetry to the generator and discriminator. In the taming-VQGAN, the implementation uses two residual blocks per stage in the encoder but three per stage in the decoder. The author adopts the symmetric architecture with two residual blocks per stage in both the encoder and decoder. Addtionally, the author aligns the number of base channels in the generator and discariminator by reducing the channel dimension of the generator from 128 to 64.
(3) Updating the learning rate scheduler. The author replaces a constant learning rate with a cosine-learning rate scheduler with warmup.
-
Increasing Model Capacity. The author increases the number of base channels from 64 to 128 for both generator and discriminator. As a result, the generator uses 17 million fewer parameters overall compared to the Taming-VQGAN baseline, while the number of parameters in the discriminator increases by only 8.3 million. Resulting in the 3.13 rFID performance improvement, from 7.15 rFID to 4.02 rFID.
-
Perceptual Loss. In Taming -VQGAN, the LPIPS score obtained by the LPIPS VGG network is minimized to improve image decoding. The author applies an $L_2$ loss on the logits solely of a pretrained ResNet50 using the original and reconstructed images. Resulting in the 1.62 rFID performance improvement, from 4.02 rFID to 2.40 rFID.
-
Discriminator Update. The original PatchGAN discriminator employs 4x4 convolutions and batch normalization, resulting in an output resolution of 30x30 from a 256x256 input and utilizing 11 million parameters (with 128 base channels). The author replaces the 4x4 convolution kernels with 3x3 kernels and switch to group normalization, maintaining the same number of convolutions while producing a 32x32 output resolution. The author then applies 2x2 max pooling to align the output stride between the generator and discriminator. In the second update, author replaces average pooling for downsampling with a precomputed 4 × 4 Gaussian blur kernel using a stride of 2 and incorporate LeCAM loss to stabilize adversarial training. Resulting in the 0.4 rFID performance improvement, from 2.40 rFID to 2.00 rFID.
-
The Final Changes. The author uses the Exponential Moving Average (EMA) which is significantly stabilizes the training and improves convergence, while also providing a small performance boost. The author also increases the number of training iterations from 300,000 to 1.35 million iterations. Resulting in the 0.34 rFID performance improvement, from 2.00 rFID to 1.66 rFID.
-
An Embedding-Free Variant. Following the Lookup-Free Quantization (LFQ) approach, author implements a binary quantization process by projecting the latent embeddings to Kdimensions (K = 12 in this experiment) and then quantizing them based on their sign values. Resulting in the 0.05 rFID performance improvement, from 1.66 rFID to 1.61 rFID.
MaskBit: A New Embedding-free Image Generation Model

-
Bit Tokens Are Semantically Structured. The author flips the $i$-th bit (i.e., swapping -1 and 1) for all 256 bit tokens and decoding them as usual to produce images. And the reconstructed images from these bit-flipped tokens are still visually and semantically similar to the original images. This indicates that the representation of bit tokens has learned structured semantics, where neighboring tokens (within a Hamming distance of 1) are semantically similar to each other. Conducting the same experiment with VQGAN leads to non-meaningful output, sharing no semantic or visual similarities with the original image.
-
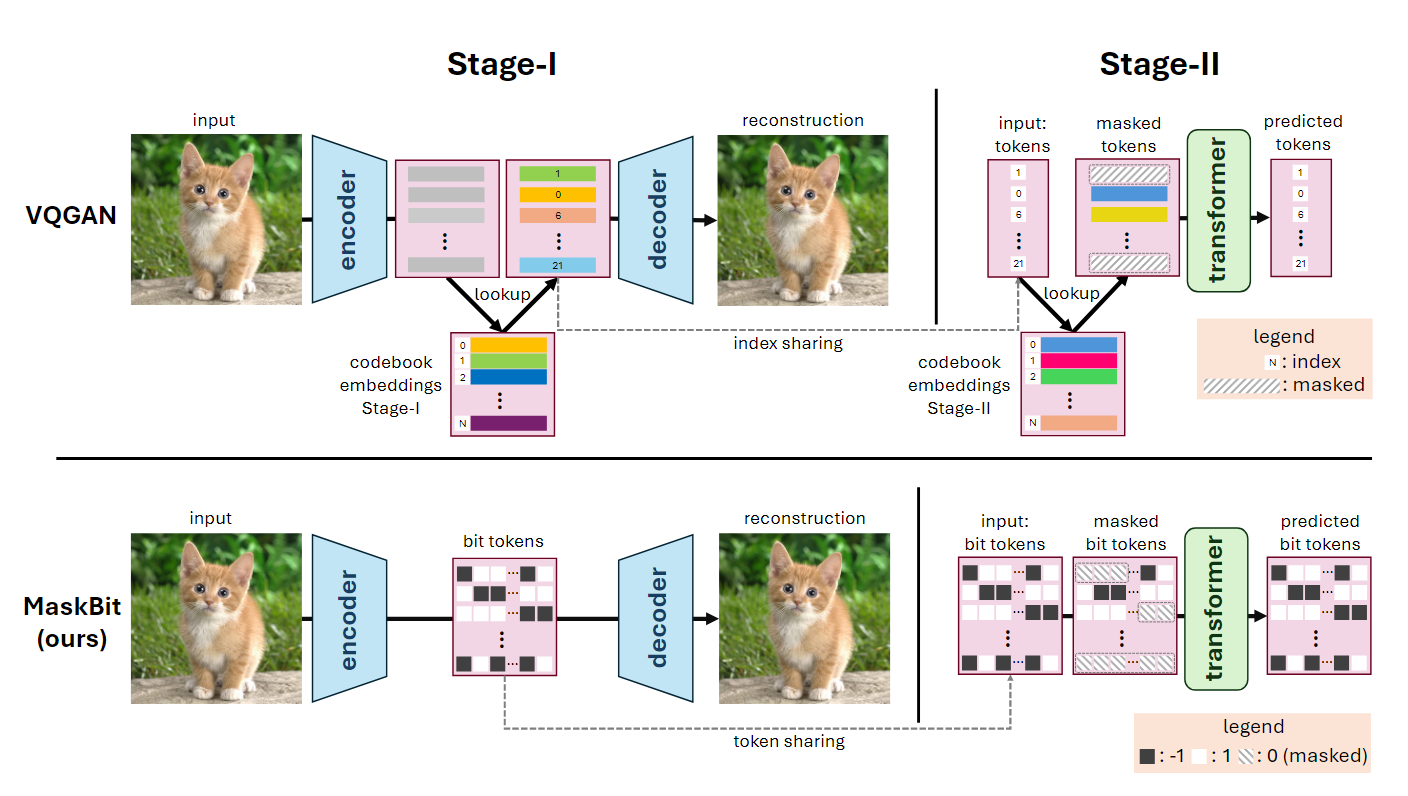
Masked Bits Modeling. Prior art using VQGAN approaches share only indices of the embedding tables between the two stages, but learn independent embeddings. Taking advantage of the built-in semantic structure of bit tokens, the proposed MaskBit can share the tokens directly between Stage-I and Stage-II. The Stage-II training follows the masked modeling framework, where a certain number of tokens are masked (i.e., replaced with a special mask token) before being fed into the transformer, which is trained ot recover the masked tokens. In particular, a bit token $t$ is represented as $t\in\{−1, 1\}^K$ (i.e., $K$-bits, with each bit being either −1 or 1), while author sets all masked bits to zero. Consequently, these masked bit tokens do not contribute to the image representation.
-
Masked “Groups of Bits” Modeling. Given that bit tokens capture a channel-wise binary quantization, author explores masking “groups of bits”. Specifically, for each bit token $t\in\{−1, 1\}^K$ , author splits it into $N$ groups $t_n\in\{−1, 1\}^{K/N}, ∀n\in\{1, · · · , N\}$, with each group contains $K/N$ consecutive bits. During the masking process, each group of bits can be independently masked. Consequently, a bit token $t$ may be partially masked, allowing the model to leverage unmasked groups to predict the masked bits, easing the training process.