Contribution
- Author develops an asymmetric encoder-decoder architecture, with an encoder that operates only on the visible subset of patches(without mask tokens), along with a lightweight decoder that reconstructs the original image from the latent representation and mask token.
- Author finds that masking a high proportion of the input image, e.g., 75%, yields a nontrivial and meaningful self-supervisory task.
What makes masked autoencoding different between vision and language?
- Architectures are different. In vision, convolutional networks were dominant over the last decade. Convolutions typically operate on regular grids and it not straightforward to integrate indicators.
- Information density is different between language and vision. Language is highly semantic and information-dense. Only few missing words per sentence can induces model to learn sophisticated language understanding. However, in images, have heavy spatial redundancy. Few missing patches can be recovered from neighboring patches, and model can learn little high-level understanding.
- The decoder of autoencoder. The decoder in vision reconstructs pixels, hense its output is of a lower semantic level than common recognition task. In contrast, teh decoder in language predicts missing words that contain rich semantic information. The decoder design in images plays a key role in determining the semantic lavel of learned latent representations.
Method
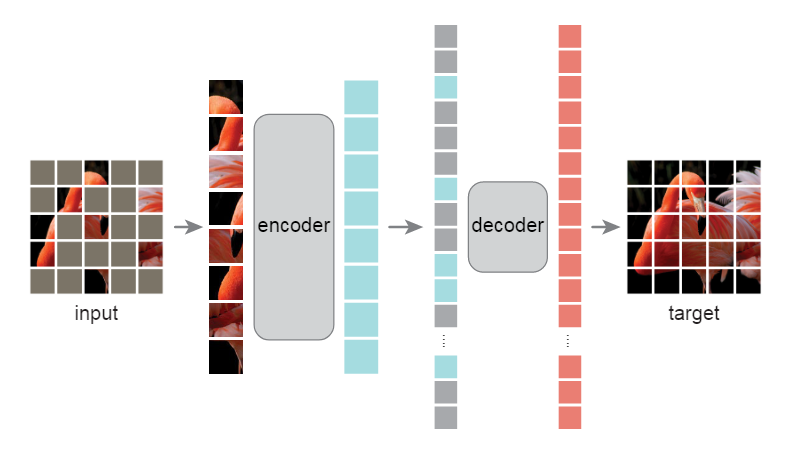
- Masking. Divide an image into regular non-overlapping patches. And than sampling a subset of patched(the scale of the subset is desided by the mask ratio) and mask(i.e., remove) the remaining patches. The sampling strategy author used is straightforward: random sampling.
- MAE encoder. The encoder is a ViT but applied only on visible, unmasked patches. Because the masked patches are dropped, the encoder only operates on a small subset(e.g., 25%) of the full set, this allows us to train large encoders with only a fraction of compute and memory.
- MAE decoder. The input to the MAE decoder is the full set of tokens consisting of (i) encoded visible patches, and (ii) mask tokens. Each mask token is a shared, learned vector that indicates the presence of a missing patch to be predicted. The MAE decoder is only used during pre-training to perform the image reconstruction task, and only the encoder is used to produce image representations for downtream tasks.
- Reconstruction target. MAE reconstructs the input by predicting the pixel values for each masked patch. Each element in the decoder’s output is a vector of pixel values representing a patch. The last layer of the decoder is a linear projection whose number of output channels equals the number of pixel values in a patch.